

مقصود اصلی از مهندسی نرم افزار تقسیم فرایند توسعه نرم افزار به مراحلی است که هر کدام از آنها روی یک منظر از توسعه تمرکز می نمایند. مجموعه این مراحل گاهی به عنوان چرخه عمر توسعه نرم افزار (Software Development LifeCycle) به اختصار #SDLC نامیده می شود.
محصول مد نظر در این چرخه حرکت می کند (گاهی مکررا بازتعریف و بازتولید می شود) تا اینکه در نهایت برای استفاده بازنشسته شود. در حالت ایده ال، هر مرحله چرخه قبل از حرکت به مرحله بعد، از نظر صحت بررسی می گردد.
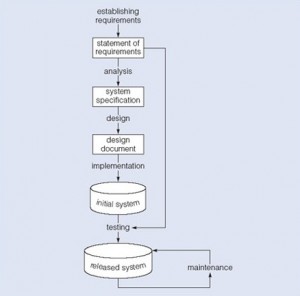
چرخه توسعه نرم افزار آبشاری
مدل فوق بیشتر در کتاب های مهندسی نرم افزار یافت می شود و می تواند درخصوص توسعه هر سیستم کامپیوتری بکار رود. این فرایند بصورت یک توالی در نظر گرفته می شود که خروجی یک مرحله ورودی مرحله بعدی است و کل یک مرحله قبل از حرکت به مرحله بعدی تکمیل می گردد.
فرایند آبشاری عبارتست از تعریف فعالیت های لازم بعلاوه ورودی و خروجی های هر فعالیت. مسئله مهم محدوده فعالیت ها می باشد. این فعالیت ها عبارتند از :
• فعالیت وضع الزامات که طبق مشورت و توافق با ذینفعان در مورد آنچه از یک سیستم می خواهند ایجاد می شود و به آن بیانیه الزامات گفته می شود.
• فعالیت تجزیه و تحلیل که با ملاحظه بیانیه الزامات شروع و با تولید مشخصات سیستم پایان می یابد. مشخصات عبارتست از الزامات رسمی سیستم مستقل از نحوه تحقق آنها.
• فعالیت طراحی که با مشخصات سیستم شروع شده ، مستندات طراحی را تولید و شرح جزئیات ساخت را ارائه می دهد.
• فعالیت پیاده سازی سیستم کامپیوتری مطابق با مستندات طراحی و با در نظر گرفتن محیطی که سیستم در آن کار خواهد کرد. پیاده سازی بصورت فازبندی انجام می شود و معمولاً با آزمایش و تایید سیستم اولیه قبل از انتشار و استفاده سیستم نهایی همراه است.
• فعالیت آزمایش که سیستم پیاده سازی شده را با مستندات طراحی و بیانیه الزامات مقایسه کرده و گزارش پذیرش را تولید کرده یا لیستی از خطاها و اشکالات تهیه می کند که جهت اصلاح ، نیاز به طی مجدد روند تجزیه و تحلیل ، طراحی و پیاده سازی دارند.
• فعالیت نگهداری شامل مواجهه با تغییر الزامات یا محیط پیاده سازی ، رفع اشکالات یا انتقال سیستم به محیط های جدید است. از آنجا که نگهداری شامل تجزیه و تحلیل تغییرات ، طراحی راه حل ، پیاده سازی و آزمایش آن راه حل در طول عمر یک سیستم نرم افزاری است ، چرخه عمر آبشاری مکررا مورد تجدید نظر قرار می گیرد.
چرخه عمر پایگاه داده
چرخه آبشاری مبنایی برای مدل توسعه پایگاه داده است که با 3 فرض در نظر گرفته می شود : 1- در توسعه پایگاه داده ایجاد مشخصات و نمای تعریف داده ها از فرایندهای مورد استفاده کاربر تفکیک می شود. 2- استفاده از معماری با سه نما برای تمایز فعالیت های مرتبط با هر کدام. 3- یکبار اعمال محدودیت های معنایی داده بجای اعمال در هر فرایند مورد استفاده کاربر.
با استفاده از این فرضیات ، نمودار شکل زیر مدل فعالیت ها و خروجی هایشان برای توسعه پایگاه داده را نشان می دهد که جهت تمام DBMS ها کاربرد دارد نه تنها RDBMS ها. توسعه نرم افزار پایگاه داده عبارتست از فرایند بدست آوردن نیازهای دنیای واقعی ، تجزیه و تحلیل نیازها ،طراحی داده ها و توابع سیستمی ، و سپس پیاده سازی عملیات.
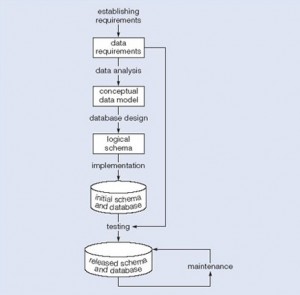
جمع آوری نیازها
طی این مرحله ، طراح پایگاه داده برای درک سیستم مد نظر ، کسب و مستندسازی نیازهای داده ای و عملکردی ، با مشتریان (کاربران پایگاه داده) مصاحبه هایی انجام می دهد. نتیجه این مرحله سندی است که شامل جزئیات نیازهای ارائه شده توسط کاربران است. وضع الزامات مستلزم این است که در بین تمام کاربران در مورد داده هایی که می خواهند ذخیره نمایند از لحاظ معنی و تفسیر عناصر داده مشورت و توافق صورت پذیرد. در این فرایند ضمن بازبینی مسائل کسب وکاری ، حقوقی و اخلاقی در سازمان که بر نیازهای داده ای تأثیر می گذارند ، راهبر داده نقش اساسی را ایفا می کند.
سند الزامات داده برای تأیید نیاز کاربران استفاده می شود. برای اطمینان از سهولت فهم آن ، نباید خیلی رسمی و یا رمزگذاری شده باشد. این سند باید خلاصه ای از نیازهای کلی کاربران باشد - نه مجموعه ای از نیازهای همه افراد ، زیرا هدف از آن ایجاد یک پایگاه داده مشترک است. الزامات نباید نحوه پردازش داده ها را شرح دهد ، بلکه بیان می کنند داده ها مربوط به چه چیزی هستند ، چه ویژگی هایی دارند ، چه محدودیت هایی دارند و چه روابطی بین اقلام داده ای وجود دارند.
تجزیه و تحلیل
این مرحله با سند نیازهای داده ای شروع شده و یک مدل مفهومی داده تولید می نماید و هدف آن توصیف دقیق داده هایی است که متناسب با نیاز کاربر هستند طوریکه هم به ویژگی های سطح بالا و هم سطح پایین داده ها و استفاده از آنها پرداخته می شود و شامل ویژگی هایی از جمله محدوده مقادیر مجاز است (مثلا ، در پایگاه داده تحصیلی ، کد دوره دانشجویی ، عنوان دوره و نمره لازم). مدل مفهومی داده نمایی مشترک و رسمی از ارتباطات بین کاربران و توسعه دهندگان حین توسعه پایگاه داده ارائه می کند که متمرکز بر داده های یک پایگاه داده است ، که صرف نظر از استفاده داده در فرایندهای کاربری یا پیاده سازی داده در محیط های کامپیوتری خاص می باشد. بنابراین ، یک مدل مفهومی داده مرتبط با معنی و ساختار داده است ، نه با جزئیات تأثیرگذار در نحوه پیاده سازی آنها.
پس مدل مفهومی داده عبارتست از نمایش رسمی داده هایی که در پایگاه داده باید وجود داشته باشند و محدودیت هایی که باید برای داده ها برآورده شوند. اینکار باید با اصطلاحاتی بیان شود که مستقل از نحوه پیاده سازی مدل باشند. در نتیجه ، تجزیه و تحلیل روی این سوال تمرکز می نماید ، "چه چیزی لازم است؟" نه "چطور بدست می آید؟"
این مدل با استفاده از نمودارهای Entity_Relationship_model ) ER ) توسط ابزارهای گرافیکی و زبان Unified_Modeling_Language ) UML ) تولید می گردد که از وظایف اولیه طراح پایگاه داده است. تولید این مدل فرایندهای کسب و کار و تحلیل چرخه های کاری سازمان را برای درک نیازهای اطلاعاتی مورد بررسی قرار می دهد. این مدل مستقل از تکنولوژی بوده و وردی مدل منطقی داده می باشد.
طراحی منطقی
این مرحله با مدل مفهومی داده شروع شده و نمای منطقی داده را تولید و نوع سیستم پایگاه داده مورد نیاز را تعیین می نماید (شبکه ای ، رابطه ای ، شیء گرا). نمایش رابطه ای مدل مفهومی داده مستقل از DBMS خاصی است و در واقع یک مدل مفهومی دیگر است که به عنوان ورودی فرایند طراحی منطقی استفاده می شود. خروجی این مرحله مشخصاتی رابطه ای است ، یک نمای منطقی از جداول و محدودیت های لازم جهت توصیف کافی داده ها در مدل مفهومی.
طی فعالیت طراحی ، مناسب ترین جداول برای نمایش داده ها در پایگاه داده انتخاب می شوند. این انتخاب ها جهت لحاظ نمودن معیارهای مختلف طراحی صورت می گیرند از جمله ، انعطاف پذیری در تغییر داده ها ، کنترل تکرار داده ها و بهترین نحوه نمایش محدودیت ها. جداول تعریف شده توسط طراحی منطقی تعیین می کنند چه داده هایی ذخیره شوند و چگونه می توان آنها را در پایگاه داده تغییر داد. طراحانی که با پایگاه داده رابطه ای و SQL آشنا هستند ممکن است وسوسه شوند بعد از تهیه مدل داده مفهومی ، مستقیماً به پیاده سازی بپردازند اما چنین کاری معمولاً به پایگاه داده ای با تمام خصوصیات مطلوب ، مانند کامل بودن ، یکپارچگی ، انعطاف پذیری ، کارایی و قابل استفاده بودن منتهی نمی شود.
در این مرحله ابتدا جداول و محدودیت های مورد نیاز طبق توضیحات مدل مفهومی داده به طور دقیق نشان داده می شود ، بنابراین تمامیت و یکپارچگی نیازها برآورده می گردد ، اما ممکن است انعطاف پذیری یا قابلیت استفاده لازم را ارائه ندهد.
شکل زیر مراحل تکراری طراحی پایگاه داده را باختصار نشان می دهد که هدف اصلی آن مشخص کردن جداول با استفاده از تعاریف عناصر تشکیل دهنده آنها است. هر تکرار که شامل تجدید نظر در تعریف جداول می باشد ، به یک طراحی جدید منتهی می شود.
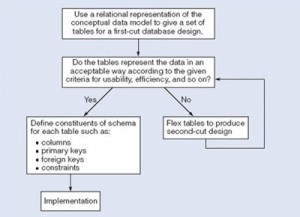
اولا درخصوص مدل مفهومی داده ، لازم نیست کلیه نیازهای کاربر توسط یک پایگاه داده واحد برآورده شود. دلایل مختلفی برای توسعه بیش از یک پایگاه داده وجود دارد ، از جمله نیاز به عملیات مستقل در مکانهای مختلف یا کنترل دپارتمان ها بر داده های خودشان. با این حال ، اگر مجموعه پایگاه داده حاوی داده های تکراری باشند و کاربران نیازمند دسترسی به داده ها در بیش از یک پایگاه داده باشند ، پایگاه داده می تواند بصورت واحد در نظر گرفته شود. دوما ، یکی از فرضیات مربوط به توسعه پایگاه های داده این است که می توان این توسعه را از فرایندهای کاربری تفکیک نمود به این دلیل که ، پس از پیاده سازی یک پایگاه داده ، تمام داده های مورد نیاز فرایندهای کاربری شناسایی و تعریف شده و قابل دسترسی هستند اما جهت نیل به انعطاف پذیری لازم ، می توان درخواست های متداول از پایگاه داده را پیش بینی و براساس آنها طراحی را بهینه کرد. سوما ، بسیاری از جنبه های طراحی و پیاده سازی بستگی به کاربرد یک نرم افزار DBMS خاص دارد. اگر انتخاب نرم افزار DBMS قبل از مرحله طراحی انجام شده باشد ، می توان از آن برای تعیین معیارهای طراحی استفاده کرد. بدین معنی که می توان به جای تهیه یک طرح کلی ، طراحی را برای یک DBMS خاص انجام داد. معمولا یک طرح واحد نمی تواند همزمان تمام خصوصیات یک پایگاه داده خوب را برآورده کند. بنابراین باید طراح این خصوصیات را اولویت بندی نماید. به عنوان مثال ، آیا یکپارچگی از کارآیی مهمتر است و یا قابلیت استفاده مهمتر از انعطاف پذیری است. در پایان مرحله طراحی ، نمای منطقی جهت تامین نیازهای کاربر با استفاده از عبارات زبان DDL در SQL تهیه می شود.
پیاده سازی
پیاده سازی عبارتست از ساخت پایگاه داده با توجه به طراحی انجام شده که شامل فضای ذخیره سازی مناسب ، اعمال امنیت لازم و غیره خواهد بود. پیاده سازی به شدت تحت تأثیر نرم افزار DBMS و محیط عملیاتی انتخاب شده است. به غیر از ایجاد پایگاه داده و اعمال محدودیت ها اقدامات دیگری نیز وجود دارند از جمله ورود داده ها در جداول ، مواجهه با مسائل مربوط به کاربران و فرایندهای کاربری و فعالیت های مرتبط با مدیریت داده ها ، که باید پشتیبانی شوند.
در عمل ، پیاده سازی نمای منطقی در یک #DBMS خاص ، نیازمند دانش کاملی راجع به ویژگی ها و امکانات آن DBMS است. در شرایط ایده ال ، اولین قدم در پیاده سازی ، تطبیق الزامات طراحی با ابزارهای اجرایی و انتخاب محصول نرم افزاری DBMS و #SQL مناسبتر جهت پیاده سازی می باشد. با این حال ، در بیشتر مواقع اینطور نیست و انتخاب سخت افزار و DBMS قبل از ملاحظه طراحی پایگاه داده انجام می گیرد. بنابراین ، پیاده سازی می تواند انعطاف پذیری بیشتر طراحی جهت غلبه بر محدودیت های نرم افزاری یا سخت افزاری را به همراه داشته باشد.
تحقق طراحی
پس از ایجاد طراحی ، پایگاه داده مطابق با تعاریف آن تولید می گردد. در پیاده سازی پایگاه های داده از دو روش برای تعریف جداول و محدودیت های لازم و تنظیم فضای ذخیره سازی استفاده می گردد. یک روش ، نوشتن دستورات زبان #DDL در SQL و اجرای آنهاست. روش دیگر ، استفاده از ابزارهای تعاملی پایگاه داده نظیر SQL Server Management Studio or Microsoft Access می باشد. به هر حال نتیجه یکی خواهد بود ، جداول و محدودیت های لازم تعریف می گردند ولی هیچ داده ای برای پردازش وجود ندارد.
تکمیل پایگاه داده
بعد از اینکه پایگاه داده ایجاد گردید، دو روش برای پر کردن آن وجود دارد یا با داده های موجود و یا از طریق استفاده از نرم افزار کاربردی. ممکن است داده های برخی جداول در فایل ها یا پایگاه های داده قبلی وجود داشته باشند یا ممکن است برخی داده از مراکز بیرونی خریداری شوند (مانند آدرس و شماره تلفن). در روش اول از قابلیت import و export و انتخاب قالب های استاندارد استفاده می شود. اگر داده ها شکل مناسب جهت ورود مستقیم به پایگاه داده را نداشته باشند باید تبدیلات لازم روی آنها صورت پذیرد. تبدیل حجم زیاد داده ها بار سنگینی به پایگاه داده تحمیل می نماید که برای کاهش این بار ، بررسی محدودیت ها پس از پایان بارگذاری کامل داده ها انجام می شود.
#software_development_lifecycle

دیدگاه کاربران
0 دیدگاهشما هم دیدگاه خود را ارسال کنید