

ویدیوهای جعلی بطور فزاینده ای برای حریم خصوصی و امنیت اجتماعی زیان بار می شوند. روشهای مختلفی برای تشخیص ویدئوهای دستکاری شده ارائه شده است. تلاش های اولیه عمدتا روی ویژگی ناسازگاری ناشی از فرآیند تلفیق چهره تمرکز داشتند. در حالیکه روشهای تشخیصی جدید عمدتاً ویژگیهای بنیادی را مد نظر قرار میدهند. همانطور که در جدول زیر نشان داده شده است، این روش ها بر اساس ویژگی های مورد استفاده به پنج دسته تقسیم می شوند. ابتدا با روش تشخیص بر اساس شبکه های عصبی عمومی که وظیفه تشخیص ویدئوی جعلی جزو وظایف عادی طبقه بندی آنها است شروع می کنیم. ویژگی سازگاری نیز برای تشخیص ناپیوستگی بین فریم های مجاور در ویدئوی جعلی استفاده می شود.

روش های عمومی مبتنی بر شبکه
پیشرفت های اخیر درخصوص طبقه بندی تصاویر، برای بهبود تشخیص ویدئوهای جعلی بکار گرفته شده است. در این روش تصاویر چهره استخراج شده از ویدئو برای آموزش شبکه استفاده می شوند. سپس شبکه آموزش دیده برای پیش بینی تمام فریم های ویدئو بکار گرفته می شود. پیش بینی ها در نهایت با استراتژی میانگین محاسبه می شوند. در نتیجه دقت تشخیص قویا به شبکه های عصبی بستگی دارد بی نیاز از بکارگیری ویژگی های خاص.
در این بخش، روش های مبتنی بر شبکه به دو نوع تقسیم می شوند: روش های مبتنی بر یادگیری انتقال (Transfer learning) و روش های تشخیص بر اساس طراحی شبکه های خاص.
یادگیری انتقال
روشهای تشخیص مبتنی بر شبکه جزو اولین روش های معرفی شده برای این وظایف می باشند. اندکی پس از ظهور اولین ویدیوهای جعلی، الگوریتمهایی که عمدتاً بر مبنای شبکههای موجود و برای طبقه بندی تصاویر عمل می کردند پیشنهاد شدند. استراتژی یادگیری انتقال را می توان به راحتی در مطالعات اولیه یافت. ترکیب ویژگیهای نهان کاوی و ویژگیهای یادگیری عمیق، یک شبکه جریانی دوسویه برای تشخیص دستکاری انجام شده ارائه نمود.
از آنجا که این قبیل الگوریتم ها بسیار توانمند بودند محققان تلاش کردند با استفاده از آنها تفاوت های ذاتی بین ویدیوهای واقعی و جعلی را از طریق پیش پردازش استخراج نمایند. ثابت شد که برخی از روش های پیش پردازش، مانند محاسبه جریان نوری، برای استفاده درخصوص تفاوت های میان فریمی مفید می باشند.
طراحی شبکه های خاص
با ظهور مجموعه داده های بزرگ و توسعه الگوریتم های تشخیص، بهبود کلیت الگوریتم های تشخیص مورد توجه قرار گرفت. نگوین یک شبکه کپسولی برای بهبود عملکرد شبکه های تشخیص معرفی نمود. همانطور که در شکل زیر نشان داده شده است تصاویر چهره ابتدا به شبکه از پیش آموزش دیده وارد می شوند. سپس ویژگی های استخراج شده وارد شبکه کپسولی پیشنهادی می شوند که شامل چندین کپسول اصلی و دو کپسول خروجی است. سازگاری ویژگی های استخراج شده توسط کپسول های اصلی توسط الگوریتم مسیریابی پویا محاسبه شده و نتایج در نهایت به کپسول خروجی مناسب هدایت می شوند. مصورسازی ویژگی های استخراج شده نشان می دهد که ترکیب شبکه های کپسولی و الگوریتم مسیریابی پویا برای تشخیص دستکاری انجام شده روی تصاویر مفید و موثر می باشد.
اگرچه این روشها در مجموعه داده های مختلف به نتایج عالی نائل شدند ولی دلایل عملکرد خوب آنها هنوز ناشناخته است. در حقیقت، شبکه های عمیق تر به نتایج بهتری نسبت به شبکه های کم عمق در نواحی مختلف دست می یابند. بطور ساده دلیل عملکرد خوب این روش شاید عمیق بودن شبکه های طراحی شده به اندازه کافی باشد.

روشهای مبتنی بر سازگاری زمانی
پیوستگی زمانی ویژگی منحصر به فرد ویدیوها است. برخلاف تصاویر، ویدیو دنباله ای متشکل از چندین فریم است که در آن فریم های مجاور وابستگی و پیوستگی قوی با هم دارند. وقتی فریم های ویدئویی دستکاری می شوند، وابستگی فریم های مجاور به دلیل نقص الگوریتم های deepfake از بین می رود، خصوصا هنگام تغییر موقعیت چهره. در این شرایط، چندین روش تشخیص توسط محققان پیشنهاد گردید. ابتدا معماری CNN-RNN معرفی شد که طی سالهای اخیر بهبود یافت.
CNN‐RNN
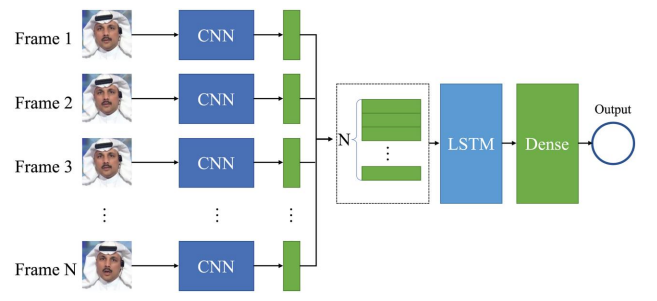
با توجه به پیوستگی زمانی در ویدئوها برای اولین بار پیشنهاد استفاده از RNN برای شناسایی ویدیوهای جعلی ارائه شد. در اینکار، رمزگذار خودکار از چهرههای قبلاً تولید شده هیچ آگاهی نداشت زیرا چهرهها فریم به فریم ایجاد شده بودند. این عدم آگاهی زمانی منجر به ناهنجاری های متعدد میشد که شواهد مهمی برای تشخیص جعلی بودن به حساب می آمدند. با بررسی مداوم فریم های مجاور، یک سیستم قابل آموزش تکرار شونده برای تشخیص ویدیوی جعلی پیشنهاد شد. همانطور که شکل زیر نشان می دهد، سیستم پیشنهاد شده عمدتاً از یک ساختار چرخشی طولانی با حافظه کوتاه مدت تشکیل شده است (LSTM) که برای پردازش سری فریم ها استفاده می شود. دو جزء ضروری به کار رفته در این ساختار، که در آن CNN برای استخراج ویژگی فریم استفاده می شود و LSTM برای تحلیل توالی زمانی استفاده می شود. آزمایشها روی مجموعه دادههای خودساخته نشان داد که این الگوریتم میتواند حتی برای ویدیویی با طول کمتر از 2 ثانیه به دقت عمل نماید.
روشهای مبتنی بر مصنوعات بصری
در بیشتر روشهای ساخت ویدئوهای جعلی، چهره تولید شده با یک تصویر پس زمینه موجود ترکیب می شود که این باعث مغایرت هایی در مرز تصاویر ترکیبی می گردد. مانند آنچه در شکل زیر نشان داده شده است این ناهنجاری ها به وضوح قابل تشخیص هستند. در اینجا سه روش اصلی بیان می شود.

بررسی تاب برداشتن چهره
مشاهده ناهماهنگی بین چهره و زمینه، یک روش جدید مبتنی بر یادگیری عمیق بود. از چهره های تاب برداشته شده تولیدی در فرآیند ادغام چهره و زمینه، برای شناسایی ویدیوهای جعلی استفاده شد. در این حالت، ناسازگاری رنگ و وضوح بین نواحی داخلی چهره با پس زمینه قابل مشاهده می باشد. چون هدف در اینجا تشخیص ناسازگاری بین چهره و پسزمینه است، با یک فرآیند ساده، نمونههای سیاه و سفید از چهره تولید شده و پس از رفع تاب خوردگی مستقیما در تصویر اصلی قرار می گیرد. برای واقعی تر شدن نمونه ها از ترکیبات مختلف رنگ بصورت تصادفی استفاده می شود. سپس تصویر با مجموعه ویدئوهای جعلی موجود مطابقت می یابد.
بررسی مرز ترکیب چهره و پس زمینه
در روش دیگر از اشعه ایکس برای تشخیص مرز بین چهره و پس زمینه استفاده گردید تا تعیین نماید آیا تصویر ورودی را می توان به صورت پیش زمینه و پس زمینه تجزیه کرد یا خیر. یعنی آیا مرز ترکیب پیش زمینه و پس زمینه دستکاری شده است.
بررسی ناهماهنگی حالت سر
در مطالعه جالب دیگر ویدئوهای جعلی که با افزودن یک بخش چهره به تصویر اصلی ایجاد شده اند مورد بررسی قرار گرفته و روش تشخیصی جدیدی مبتنی بر ژست های سه بعدی چهره پیشنهاد گردید. آنها استدلال کردند که شبکه های عصبی مولد نمی توانند انطباق مرز اتصال را به درستی انجام دهند و این باعث مغایرت مرز اتصال بخش الصاق شده با کل ناحیه چهره اصلی می گردد. در این روش از چرخش ماتریس بخش الصاقی در تصویر اصلی برای تحلیل شباهت بین ژست های چهره اصلی و چهره ایجاد شده استفاده می گردد.

دیدگاه کاربران
0 دیدگاهشما هم دیدگاه خود را ارسال کنید